Optimal Policy and Bellman Optimality Equation
本节内容
- 核心目标:最优 state value 与最优策略
- 基础工具:Bellman 最优方程
Motivating examples
回顾 state value 和 action value 的例子
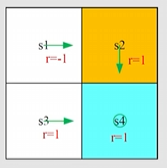
根据上述确定的策略、状态转移、奖励分布,由如下 Bellman 公式
取 则求解 Bellman 方程解如下:结果表示越靠近目标state value 越大
得到每个状态下的state value 后计算action value
发现问题:这个例子在 时的策略 是不太好的,因为右走是禁止区域。应该如何优化策略?
解决:假如选择最大的action value,那么就可以产生一个新的决策:
其中
为什么这能够优化策略?
虽然action value 能够用来评估action 的好坏,但上述的优化是基于其他状态已经是最优策略的情况下进行的。如果其他状态下的策略是随机的或者不是最优的呢?数学上可以保证只要重复迭代,(每个状态都选择action value 最大的action,然后新的action 构成新策略,利用这个策略再迭代得到新策略)一定会得到最优策略
Definition of optimal policy
State value 能够衡量策略的好坏,因为Bellman 方程是对 action value 的平均,如果策略使得平均行动都价值高,则该策略是好的:
定义
一个决策 是最优的,如果
提出定义后,就会自然产生问题:
- 最优策略存在?
- 最优策略唯一?
- 最优策略随机还是确定?
- 如何得到最优策略?
Bellman Optimality Equation
1.BOE:introduction
由策略好坏的定义,Bellman 方程中应该取使得 state value 最大的决策
Element form
Matrix form 以简洁的方式刻画了最优策略和最优 state value
问题:求解算法、存在性、唯一性、与最优策略有什么关系
2.BOE: Maximization on the right-hard side
BOE 存在未知量 ,存在需要最大化的策略 ,因此可看成一个式子两个未知量
example 1 (如何求解一个方程中的两个未知变量)
考虑有未知变量为 的方程
- 先对右侧求解 ,此时
- 方程变为 ,进而求解的
- 因此方程解为
可以先给定一个初值 ,则公式可化简,因此可有上述顺序求解方程,(后面又数学证明保证迭代收敛性)
example 2 (如何求解 )
考虑给定 的情况下求解 ,其中 , 且 ,假设
- 因为
- 则最优解为
由 example 2 可知
则最优策略为
3.BOE: Rewrite as
由于 BOE 方程时 的函数,可以写成下式矩阵形式。
其中 的元素为:
4.Contraction mapping theorem
相关概念
不动点:若 ,则称 是 的不动点
压缩映射:若 , 则称 是一个压缩映射
- 必须严格小于 1,因此 被 控制
- 为向量范数
相关概念的相关例子
易得:
- 为 的不动点
- ,故 为压缩映射
矩阵形式时,
- 仍然是不动点
- , 为压缩映射,这倒没推导过
压缩映射定理:
如果 是压缩映射,则存在唯一不动点,且可通过点序列 递归迭式 满足
5.BOE:solution
回过来看 Bellman 方程:
可以证明 是一个压缩映射!则可以使用压缩映射定理exist unique 的不动点 ,且可通过序列 和迭代式 进行求解,给定任意初值 序列 会快速收敛到 ,收敛速度取决于
假设 是 Bellman 方程的解,则
此时的最优策略为
因此得到 Bellman 最优方程(BOE)
- BOE 是特殊的 Bellman 方程
- 是最优策略(为什么?)
- 其中 是最优策略对应的state value(state value 是所有决策中最大的吗?)
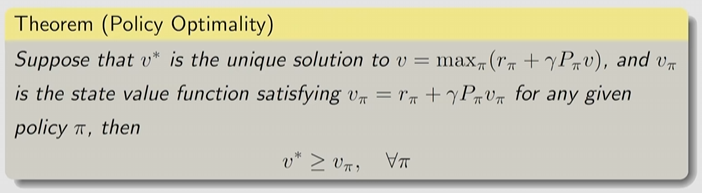
6.BOE:optimality
最优策略具体是怎样?实际上在第 2 节中的求解例子已知

Analyzing optimal policies
最优策略的影响因素有哪些?如下 BOE
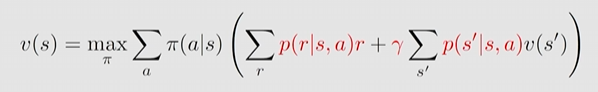
策略 与 的计算结果由红色部分影响:
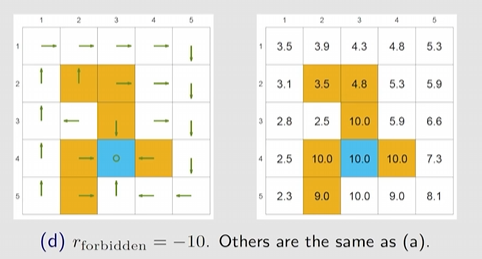
- 奖励设计:
- 系统模型:
- 折扣率:
example 1 参数 的影响
由下图可知(a) 的最优策略是会进入forbiden区域的,但是如果设置更小的 ,则(b)会避免进入forbidon 区域。
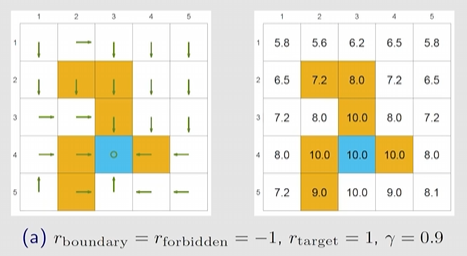
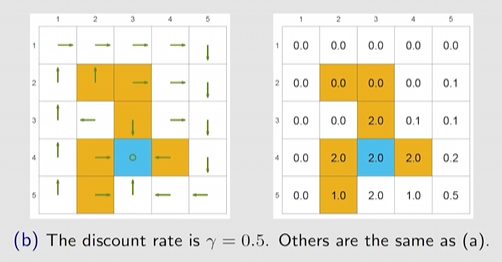
原因:
考虑 trajectory:
其 return 计算:
求 return 的期望,即状态价值:
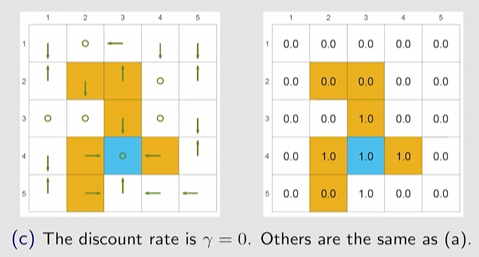
- 显然 越大,则越近视,
- 越小,只看相对大小,相对来说是远处的奖励权重相对的便重要了!
- 极端的若 如下图,只关注瞬时奖励,极其短视
Example 2 参数 的影响
显然瞬时惩罚变得更重后,绕路的 return 会大于走捷径的 return,因此会绕路
若对奖励做线性变换 后如何?答案是不会改变,因为策略选择过程中是看相对好坏。数学证明如下,具体在书中:

Example 3 绕路
下图说明绕路的策略会使得 更小,即绕路更差、
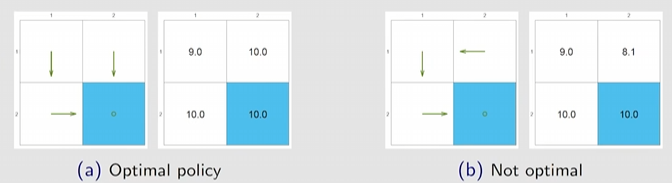
可能的提问,从 出发,既然白色区域没有惩罚,为什么绕路会更差?因为:
Policy 1:
Policy 2:
Summary
- Bellman 最优方程的 elementwise form:
- Bellman 最有方程的 matrix form:
- 通过压缩映射定理,BOE 存在唯一的解(策略不一定唯一)
- 通过压缩映射定理,可用迭代算法收敛到最优策略和最优的解
- BOE 的意义:因为因为该解的 state value 和 policy 都是最优的