- 需要修改 eval 函数,顺序为 acc auc rmse
- 函数 trian 函数需要加入
root_dir - 函数 trian 需要调整 print 顺序,注释 loss 的 print,在验证的时候加入以下代码保存路径
if float(np.mean(losses)) < bestLoss:
bestLoss = float(np.mean(losses))
self.save(os.path.join(save_dir,"best_mirt.pth"))输入数据对算法的影响
DINA
经过测试原始代码
-
数据集:a 0910
- 输入:user 和 item 和 know从 1 开始
- 初始填写
- user_num = 4164
- Item_num = 17747
- Know_num = 123
- 使用修正后的模板(上述参数的确定是根据输入的数据计算的)
- User_num = 4129 (计算 user 的最大的 id+1)
- Item_num = 17747 (计算所有作答数据中最大的 id+1)
- Know_num = 123 计算知识点
-
数据集:assis_0910
- 输入:user 和 item 和 know 从 0 开始
- 使用修正后的模板
- User_num = 2493
- Item_num = 17671
- Konw_num = 122
-
修正后的 baseline 模板算法代码
get_knowledge_nums函数中的输出np.max改成len,使 122→123code2vector函数中vector[k-1]=1改成vector[k]=1,新数据知识点从 0 开始,所以不用-1 了,这样使得 Q 矩阵正常- Dina 模型的 user_id 和 item_id 都不用在意是否从 01 开始,因为最终的能力诊断 是根据 user_id 进行 emmbedding:用 1 进行编码就用 1 来提取,用 0 进行编码就用 0 来索引。只要保证用的索引是来自输入数据的 id 即可
NCDM
为了适应从 0 开始的数据
- 修正
transform中的knowledge_emb[idx][np.array(item2knowledge[item[idx]]-1)] = 1.0改成knowledge_emb[idx][np.array(item2knowledge[item[idx]])] = 1.0torch.tensor(user, dtype=torch.int64) - 1改成torch.tensor(user, dtype=torch.int64)torch.tensor(item, dtype=torch.int64)-1改成torch.tensor(item, dtype=torch.int64)
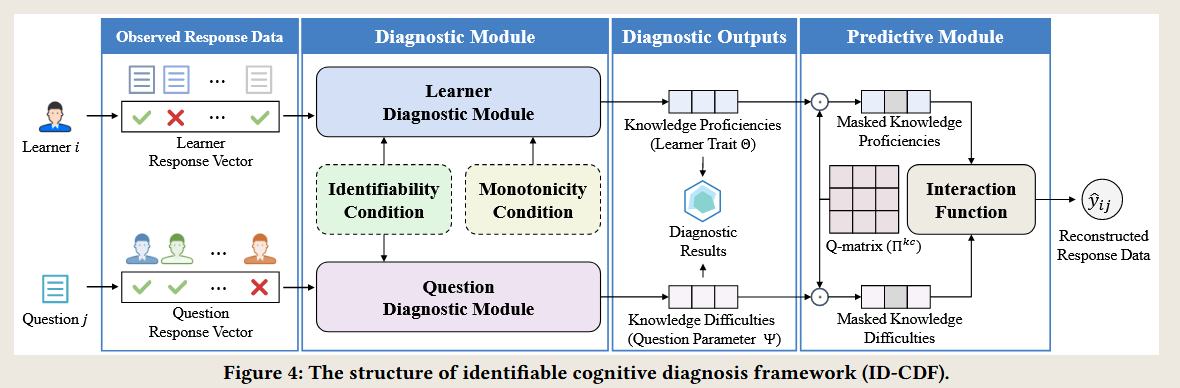
ID-CDF
- 问题 1
- 该模型中涉及到对三元组数据 csv 转变成 R,然后按行按列提取
- 但若直接使用 DINA, IRT, MIRT, NCD, KaNCD,我们处理数据集删除小于 15 题目的样本
- 因此剩余的数据会产生没人做过的题目!
RCD
ICDM
一个数据跑五遍
运行代码前的步骤
- 首先要有相应数据训练出来的
NCDM_psi和NCDM_theta - 然后需要将原数据转成无标题、
train,valid,test的user_id合并的数据 - 然后将
Q_mat.npy改成
超参数设置
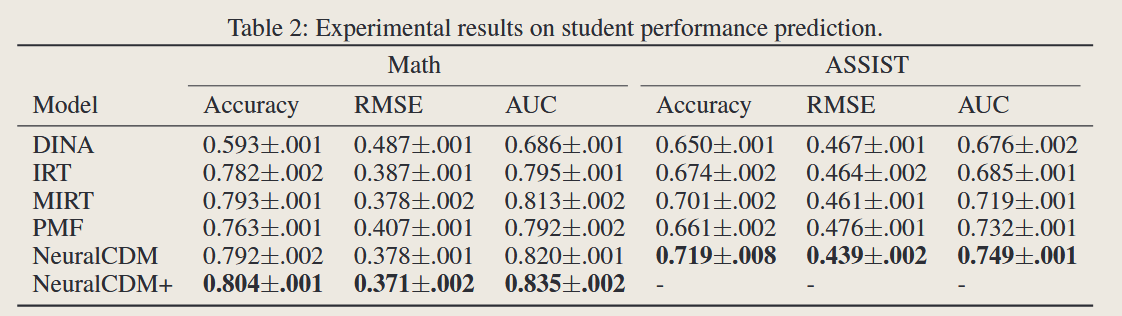
Dataset : Assisment 2009-2010
| 算法 | Lr | Epoch | Batch size |
|---|---|---|---|
| DINA | 0.001 | 40 | 64 |
| NCDM | 0.001 | 10 | 64 |
Dataset: Assisment
DINA epoch 120
模型对 Inductive 的输入修改
- 首先需要对 dataset 进行处理
RCD
大体运行步骤
- 首先运行
NCDM,RCD 输入数据是什么就输入什么 - 然后运行
train.py,这是蒸馏模型,利用编码器蒸馏 NCDM 的 theta
细节
- 首先需要修改
pretrainmodel_parser,方便批量运行 - 预训练模型
train.py修改,数据导入部分 dataset.py处理部分- 后期跑 5 个 epoch
常用的修改代码
def get_eval_result(y_true, y_pred, y_pred_label, test = False):
'''
Compute the the acc, auc, rmse in Val_set or Test_set :param y_true: label
:param y_pred: the prediction from model :param y_pred_label: transfrom y_pred to 1 or 0 :param test: testset or not ''' acc = accuracy_score(y_true, y_pred_label)
auc = roc_auc_score(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
f1 = f1_score(y_true, y_pred_label)
if test:
print('test_acc = %.4f auc = %.4f rmse = %.4f f1 = %.4f '%(acc, auc, rmse,f1))
result = {'test_acc': acc, 'auc': auc, 'rmse': rmse, 'f1': f1}
else:
print('val_acc = %.4f auc = %.4f rmse = %.4f f1 = %.4f '%(acc, auc, rmse,f1))
result = {'val_acc': acc, 'auc': auc, 'rmse': rmse, 'f1': f1}
return resultmsg = "epoch:{} train_acc:{:.4f} Lcontra:{:.4f} \n val_acc:{:.4f} auc:{:.4f} rmse:{:.4f} f1:{:.4f} \n".format(
epoch+1,
result_per_epoch['train_acc'],
result_per_epoch['Lcontra'],
eval_result['val_acc'],
eval_result['auc'],
eval_result['rmse'],
eval_result['f1']
)- RCD 的消融实验同时跑
- 首先确定好数据,跑 ED 的 train,EAD 的 train
- 然后选择最好的 5 次模型中的模型,跑 EDRCD 和 EADRCD
- 确定了参数后跑消融需要 20 小时
- 一份数据的 ED 和 EAD 跑完应该就可以不用跑了,最多跑 09,math 1,math 2 三份数据的基础模型,大概 2 h 内
- 3 份数据中跑 5 次 EDRCD 和 EADRCD,即 3×5×2=30 轮,一轮大概 35 min 内。即确定好参数后跑完所有数据需要 30×35=18 小时!
- 考虑到不是集中在跑,因此分散到 3 天才能跑完
- 还有 Inductive